A ten-step, training-free walkthrough that turns a frozen OpenAI text embedding into clean classifications: a multiclass relevance score sorts events into local, national, and global buckets, and a contrastive binary score splits systemic from idiosyncratic risk. Verified on real warnings from NOSIBLE World, the geometry matches Google's gemini-2.5-flash while staying deterministic, auditable, and effectively free.
2026-06-1814 min read
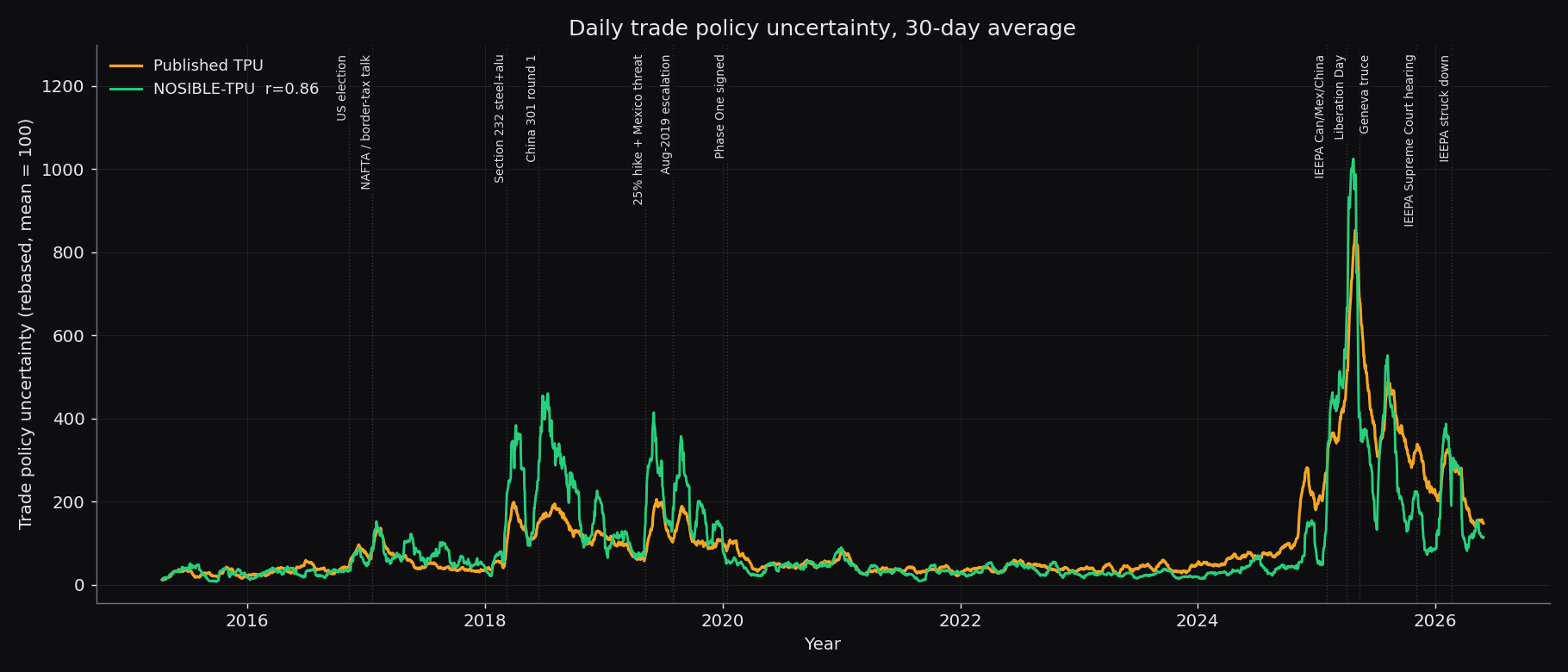
The Fed's Trade Policy Uncertainty index counts keywords across seven newspapers. We rebuilt it from 14.9 million NOSIBLE World events using only embeddings and five sentences, no keywords. It matches the published benchmark at 0.87 on monthly levels and 0.82 on monthly changes, as closely as the two official versions match each other. The same method, extended to sixty sentences, rebuilds the broader Economic Policy Uncertainty index and its national-security and healthcare categories.
2026-06-1723 min read
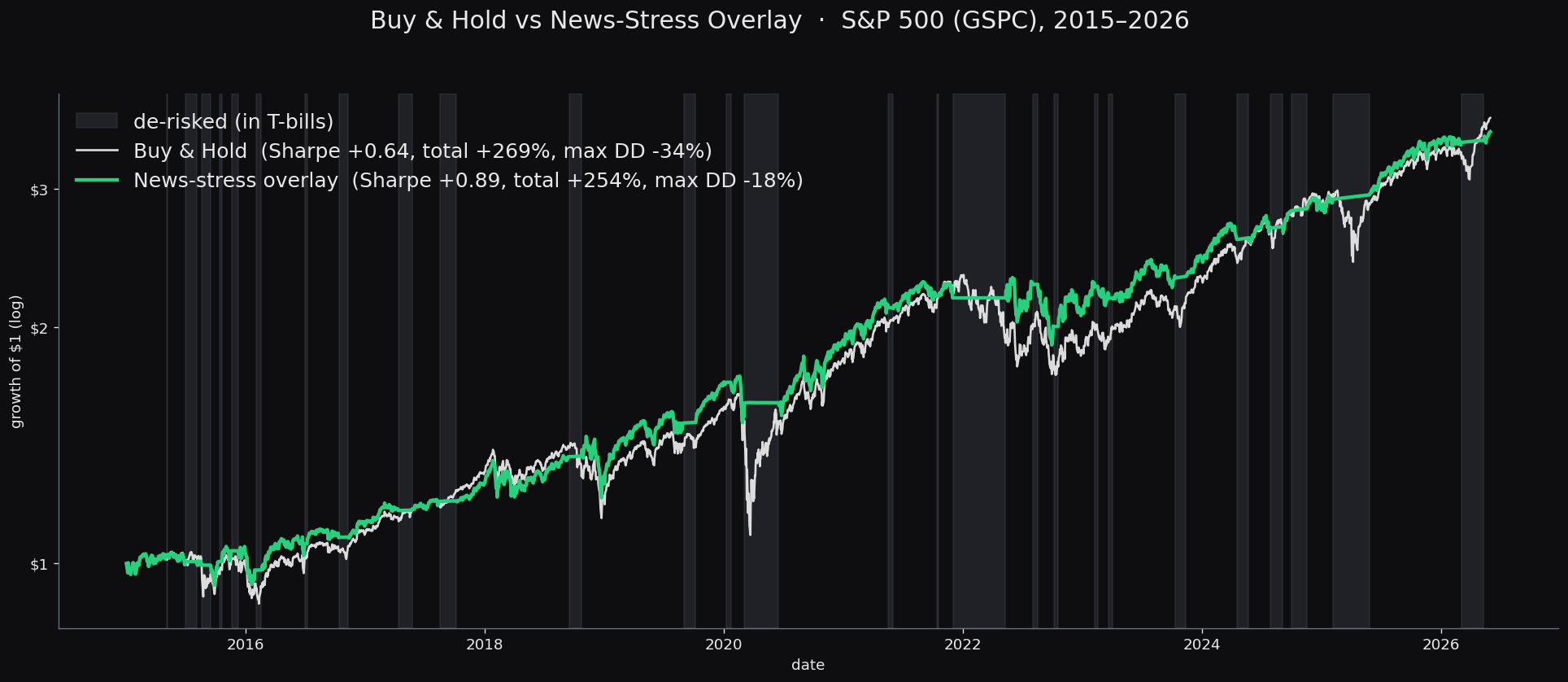
We built a risk-on/risk-off trading signal from the NOSIBLE event database that measures how much of the global news flow is about market-stress themes, holding equities when that reading is low and moving to T-bills when it spikes. Selected on 2010 to 2013 and tested on an untouched 2015 to 2026 window, it held the S&P 500's buy-and-hold return (+254% versus +269%) while cutting the maximum drawdown from −34% to −18% and raising the Sharpe ratio from 0.64 to 0.89. The same rule transfers unchanged to the Nasdaq and the Russell 2000.
2026-06-169 min read
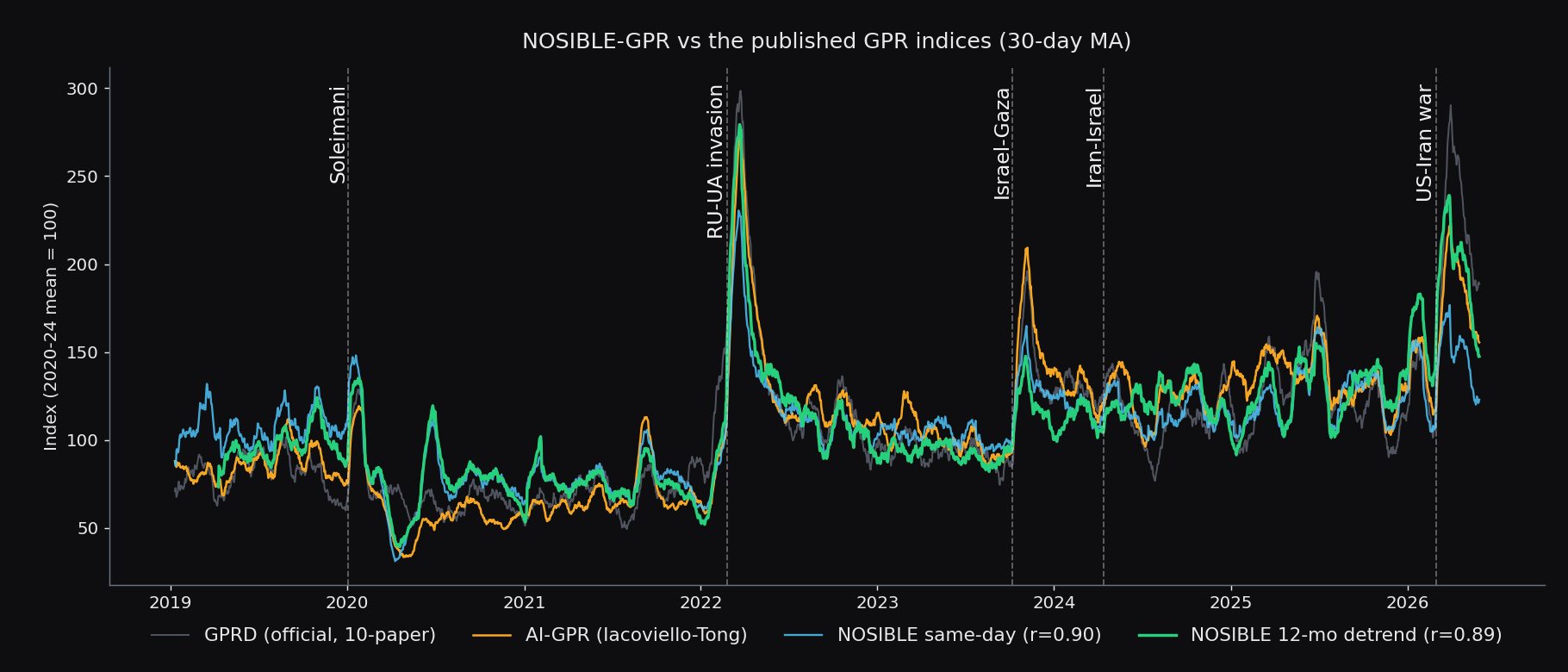
Markets move on geopolitics, but risk models cannot read the news. We turned 13.2 million news events into a geopolitical risk signal, matched the Federal Reserve benchmark, and broke it down by country, by country pair, and into an oil supply-risk signal.
2026-06-0615 min read
Here's how we fine-tuned Qwen3 0.6B to beat FinBERT and match GPT-5.1 accuracy. Complete with open-source models, datasets, and training scripts. Spoiler alert: active learning is all you need.
2025-12-1227 min read
Can Faceted Search at Web-Scale Self Organize? As it turns out, yes it can! In this post we outline our new and improved adaptive named entity tagging system!
2025-10-167 min read
Cybernaut-1 combines our powerful hybrid-3 search algorithm with LLM-guided Monte Carlo Tree Search to deliver world class search results on difficult queries.
2025-08-262 min read
AI needs its own search engine. This is how we’re rebuilding search for AI -- and the road to Cybernaut-1, the first high-trust agentic search engine.
2025-08-2017 min read
We introduce the ensemble and distil data pattern and use it to fit an ordinary least squares linear regression that outperforms GPT-4 at financial news sentiment classification using sentence transformer embeddings as features.
2024-02-0612 min read
A comparison of sentiment classifications made by TextBlob, VADER, Flair, SigmaFSA, FinBERT, FinBERT-Tone, Text-Bison, Text-Unicorn, Gemini-Pro, GPT-3.5, GPT-4, and GPT-4-Turbo. We look at accuracy, time, and cost and include a dataset of 10,368 labelled news stories (with code) for our followers.
2024-01-2813 min read
How we use vector search to extract investment signals from a multi-terabyte company news dataset that currently contains over 55 million embeddings, 150+ million sentences, 4+ billion words, and 5+ billion GPT tokens.
2024-01-2121 min read